inno.teach
Workshop-Rückschau - Distant Reading in Literary Studies. An Introduction to Tools for Data Literacy. Bielefeld, 7. Dezember 2022
Ein Beitrag von Robin-M. Aust
›Das Digitale ist aus den Literatur-, Kultur- und Geisteswissenschaften inzwischen nicht mehr wegzudenken.‹ Auch, wenn dieser Satz gleichermaßen phrasenhaft daherkommt wie der Begriff des ›Digitalen‹ unbestimmt ist, haftet ihm viel Wahres an. Das lässt sich leicht an der Vielzahl von digital generierten Kunstwerken und der momentanen Popularität von Text-KIs wie ChatGPT belegen – ebenso aber auch an Tagungen zu Aspekten der Netzkultur, Einführungsbänden zu Methoden der Digital Humanities oder dem vermeintlichen ›Revival‹ der empirischen, diesmal digital gestützten Literaturwissenschaft. Kurzum: Kunst, Öffentlichkeit und Forschung haben neuerdings ein unbändiges Interesse am Digitalen, seinen Erzeugnissen und seinen Potenzialen. Um direkt ein – zum Thema passendes – textstatistisches, wenngleich nicht repräsentatives Beispiel zur Untermauerung dieser These zu liefern: Im Gesamtprogramm des Germanistentages 2022 findet sich der Begriff ›hermeneut*‹ 37 mal, ›gegenwart*‹ 45 mal, ›mittelalter*‹ 60 mal, ›diskurs*‹ 84 und ›digital*‹ 85 mal.
In der universitären Lehre hält diese frische Entwicklung ebenfalls, wenn auch zögerlich Einzug – das Digitale wird als Thema unterrichtet, aber noch selten als Methode. Ein Grund hierfür liegt ironischerweise gerade in der ›Frische‹ der Entwicklung: viele Lehrende wurden mit den Methoden, die sie unterrichten und den Studierenden näherbringen möchten, während ihrer eigenen Ausbildung schlichtweg selbst nie konfrontiert. Dies gilt insbesondere für die Methoden der digital humanities, die Methoden aus u.a. Statistik und Informatik mit denen der Geisteswissenschaften zusammenbringen – und damit zwei traditionell eher disparate Disziplinen miteinander vereinen, mit denen sich Forschende des jeweils anderen Fachgebiets eher selten beruflich beschäftigen (müssen).
Abhilfe schaffen konnte hier der Workshop ›Distant Reading in Literary Studies. An Introduction to Tools for Data Literacy‹, der am 7. Dezember in Bielefeld stattfand. Organisiert wurde der Workshop von den BiLinked Communities of Practice »Data Literacy« sowie »Public Humanities«, Prof. Dr. Berenike Herrmann, Dr. Matthias Buschmeier sowie Dr. Alan van Beek von Dr. Giulia Grisot und Dr. Simone Rebora. Auch wenn die Grippewelle weder vor Teilnehmer*innen noch vor den Workshopleiter*innen Halt gemacht hat und krankheitsbedingt Giulia Grisot und Simone Rebora die Leitung des Workshops alleine übernehmen mussten, fanden sich an jenem Wintermorgen eine Gruppe interessierter Wissenschaftler*innen ein, um in grundlegende Perspektiven, Praktiken und Programme der digitalen Literaturwissenschaften und des Distant Readings eingeführt zu werden.
›Distant reading‹ also. Der Begriff mag vermutlich der*dem einen oder anderen Literaturwissenschaftler*in als in eine fesche Wortschöpfung verpackten Affront gegen eine sorgfältige Textlektüre und -Interpretation daherkommen und die Zornesfalte in die Stirn graben, umschreibt aber einen äußerst gewinnbringenden Komplex aus quantitativen Analysemethoden auf große Textkorpora. Die Methoden und Zugriffe, die unter dem Begriff ›distant reading‹ zusammengefasst werden, sind dabei ebenso vielfältig wie die Fragestellungen, die sie beantworten können.
Der Workshop nun sollte dabei eine erste Orientierung sowohl innerhalb der möglichen Forschungsfragen als auch der dazu passenden Analysemethode bieten. Nach einer Einführung in die Fragestellungen und Perspektiven des Distant Readings folgt schließlich direkt der erste von vier zentralen Themenblöcken: Dr. Grisot und Dr. Rebora zeigen den Workshopteilnehmer*innen zunächst, wie Worthäufigkeiten innerhalb eines ausgewählten Korpus visualisiert werden können. Mit den im weiteren Verlauf der Session erstellten Word Clouds wurden die meisten Teilnehmer*innen sicherlich bereits konfrontiert – seltener jedoch mit den Programmen und Verfahren, diese auch selbst herzustellen.

Auf dem Programm stand folglich zuerst eine Einführung in die Statistikprogrammiersprache R und die Benutzung der dazugehörigen Entwicklungsumgebung RStudio. Auch wenn das Programm auf dem ersten Blick wenig anfänger*innenfreundlich daherkommt, waren alle Teilnehmer*innen nach der Anleitung von Dr. Rebora und Dr. Grisot doch bald mit der Benutzung vertraut, sodass sie bereits eigene Word Clouds erstellen und die Parameter der dazugehörigen Skripte nach Bedarf verändern konnten. Besonders teilnehmer*innenfreundlich war auch die Entscheidung der Workshopleiter*innen, auf eine eigens erstellte Cloud-Variante von RStudio zu setzen. So stand für jede*n Teilnehmer*in eine vorkonfigurierte Umgebung inklusive vorbereiteter Korpora bereit, die lediglich nur noch im Browser aufgerufen werden musste – ohne dabei die sonst eher leidige, im Workshopkontext zeitaufwändige Installation (inkl. aller Abhängigkeiten) durchziehen zu müssen.
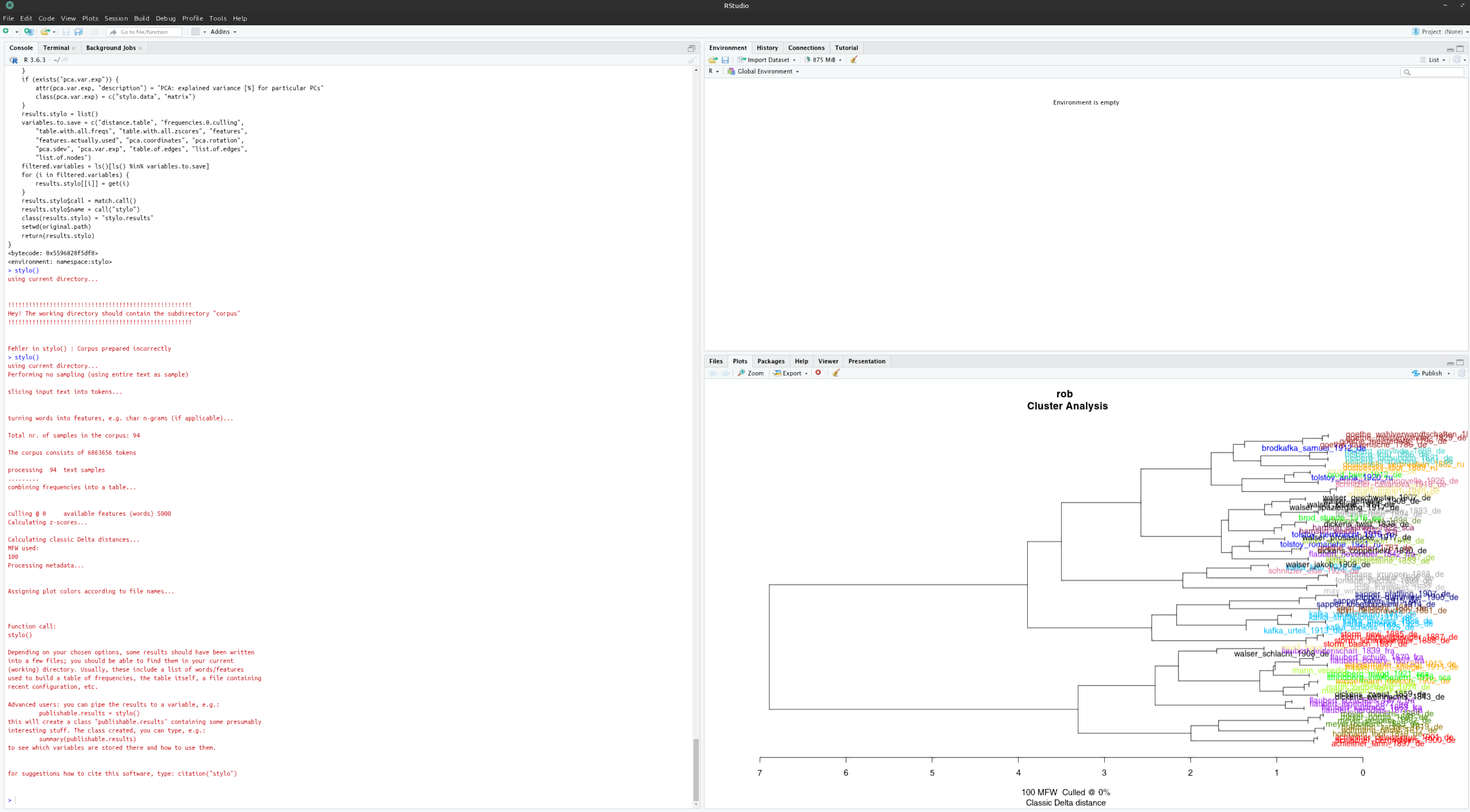
Mit den ersten Schritten in RStudio vertraut und den ersten Wordcloud-Ausgaben ausgestattet ging es direkt an den nächsten Programmpunkt: Keyword (oder Keyness) Analysis mit R und Quanteda. Erneut ging es hier um Worthäufigkeiten – diesmal aber in einer komplexeren Art und Weise: Keyness Analysis vergleicht die Worthäufigkeiten in einem Text (oder Subkorpus) mit der eines größeren oder übergeordneten Referenzkorpus. So können stilistische, thematische, inhaltliche, etc. Eigenheiten und Gemeinsamkeiten auf der Wortebene identifiziert, visualisiert und interpretiert werden.
Stilistische Eigenheiten standen auch nach der Mittagspause im Fokus des dritten Themenblocks: Wie auch die Literaturwissenschaften im Allgemeinen beschäftigt sich auch die digitale Literaturwissenschaft zentral mit Autorschaft und Autorstil. Erneut bilden hier Worthäufigkeiten die Grundlage der Analyse, die weiterverarbeitet Aufschluss über die stilistische Ähnlichkeit von Texten geben können: einer der vorgestellten Zugriffe ist die Errechnung des sogenannten Burrows-Delta, das die relative ›Entfernung‹ von Texten auf Basis diskreter Funktionsworte zueinander ausgibt. Auch hier bietet RStudio mit dem Stylo-Paket erneut eine benutzerfreundliche Möglichkeit, Texte innerhalb eines Korpus zu vergleichen und ihre relative Nähe zueinander in Dendrogrammen direkt auszugeben, ohne dass die so errechneten, für die meisten Anwender*innen eher abstrakten Datensätze selbst weiterverarbeiten zu müssen.
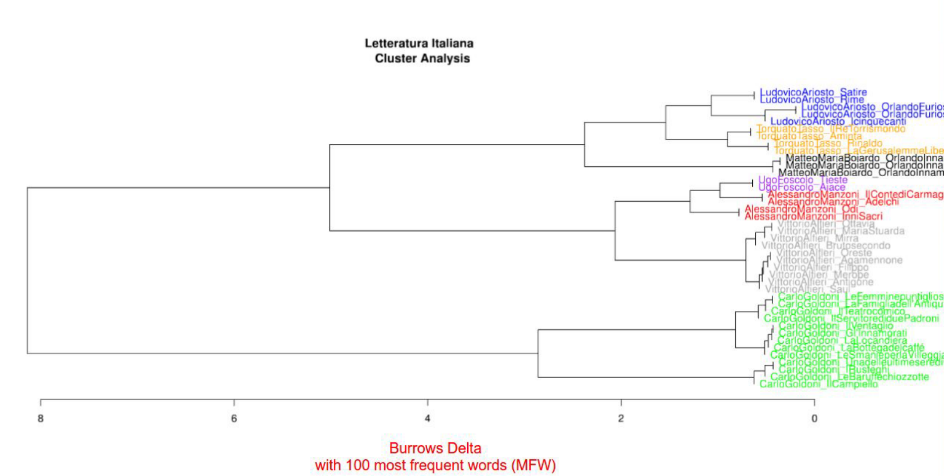
›Datensätze‹, ›Dendrogramme‹ und ›Delta‹ klingen nun allesamt nicht nach dem Methodenrepertoire der Geistes- oder Literaturwissenschaften. Dass diese digitalen Zugriffe nicht nur ihre Berechtigung, sondern auch einen unzweifelhaften Nutzen bei der Beantwortung diverser Forschungsfragen haben, zeigen die von Dr. Rebora und Dr. Grisot angeführten Anwendungsbeispiele und Fallstudien.
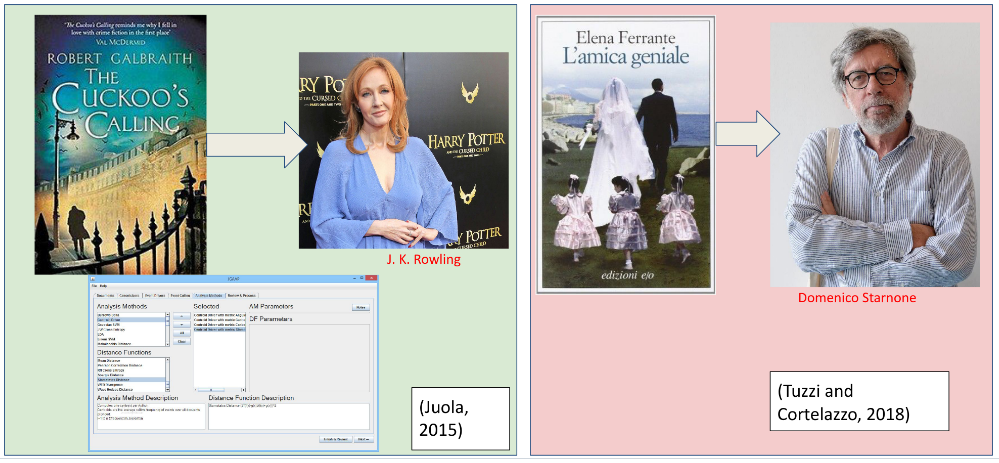
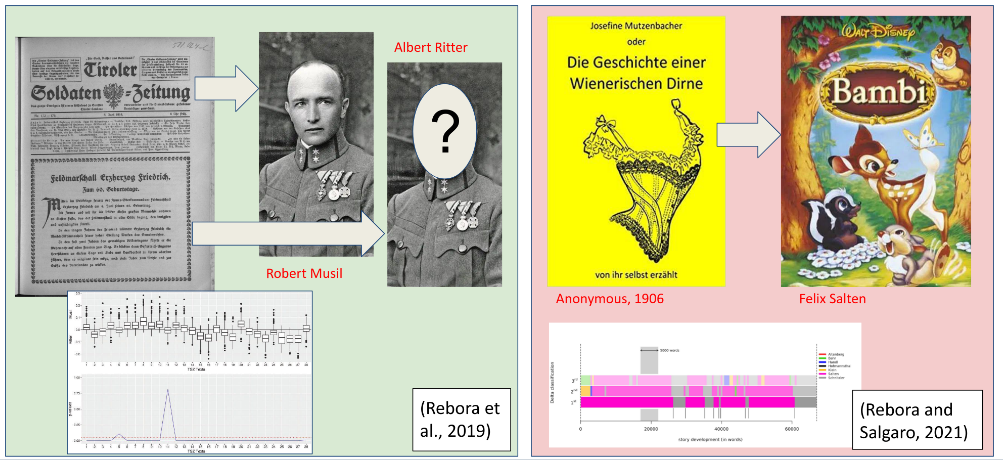
Der Anwendungsbezug wurde aber nicht nur durch Beispiele hergestellt. Insbesondere Informatiker*innen wissen: Trockenübungen sind schön und gut, learning funktioniert im Falle von Code am besten by doing. So war auch in diesem Workshop natürlich Zeit, die einzelnen Methoden und Programme selbst hands on auszuprobieren und die Parameter oder Primärtexte auf eigene Fragestellungen hin anzupassen.
Der vierte Programmpunkt beschäftigte sich letztlich mit der Sentiment Analysis, also der Quantifizierung (und natürlich erneut: Visualisierung) von Emotionen in Texten oder Textabschnitten in R und RStudio. Auch in diesem Falle blieb Zeit für Fragen und die Diskussion von Potenzialen und Grenzen des Zugriffs: thematisiert wurde unter anderem der dem jeweils verwendeten Sentiment-Wortschatz inhärente Bias und das Problem der ›klassischen‹ Sentiment-Analyse, indirekt oder ironisch formulierte Meinungen zu identifizieren.
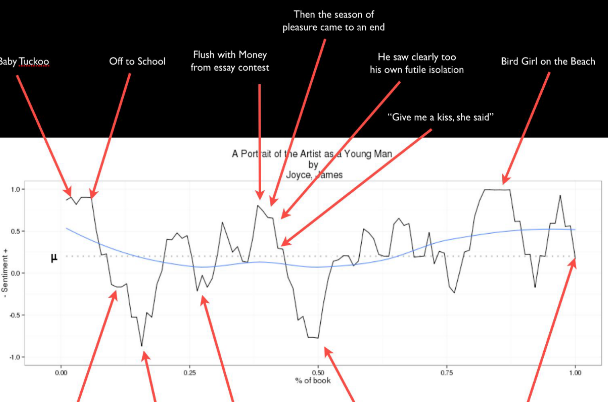
Apropos Stimmung: Die Teilnehmer*innen dieses Workshops können durchaus zufrieden sein, ist es Rebora und Grisot doch gelungen, in einem sehr begrenzten Zeitraum ein breites Panorama digitaler Analysemethoden zu präsentieren und in einem forschungspraktischen Kontext zu verorten. Eine möglicherweise vorher vorhandene Skepsis gegenüber abstrakt oder rein informatisch erscheinenden Verfahren konnte hier ebenso ausgeräumt werden wie die durchaus verständliche Überforderung, die hierfür nötigen Programme auch anzuwenden und die dazugehörigen Skripte auf eigene Fragestellungen hin anzupassen. Nicht nur der souveräne, sondern auch der kreative Umgang mit digitalen Tools im Bereich der Geisteswissenschaften bietet schließlich viel Potenzial, durch andere Methoden gar nicht erst effizient zu bearbeitende Fragen zu beantworten oder explorativ Muster und Phänomene zu identifizieren, die anderweitig gar nicht erst sichtbar würden. Kompetenz und Begeisterung für digitale Methoden in Forschung und Lehre sind natürlich auch hier die Katalysatoren weiterer Entwicklungen, derer sich auch die Geistes- und Literaturwissenschaften nicht verschließen sollten. Wer sich daher selbst informieren und das eine oder andere ausprobieren möchte, findet die Ressourcen zum Workshop nach wie vor auf der dazugehörigen Homepage.